

簡単
OCRmyPDFは、スキャンしたPDFファイルにOCR(光学式文字認識)テキストレイヤーを追加し、検索やコピーペーストができるようにするために設計されたオープンソースツールです。複数の言語をサポートし、PDFファイルのサイズを最適化し、元の画像の解像度を維持することができます。このプロジェクトはGitHubで26.8k以上のスターを獲得しており、開発者の間で広く人気があります。
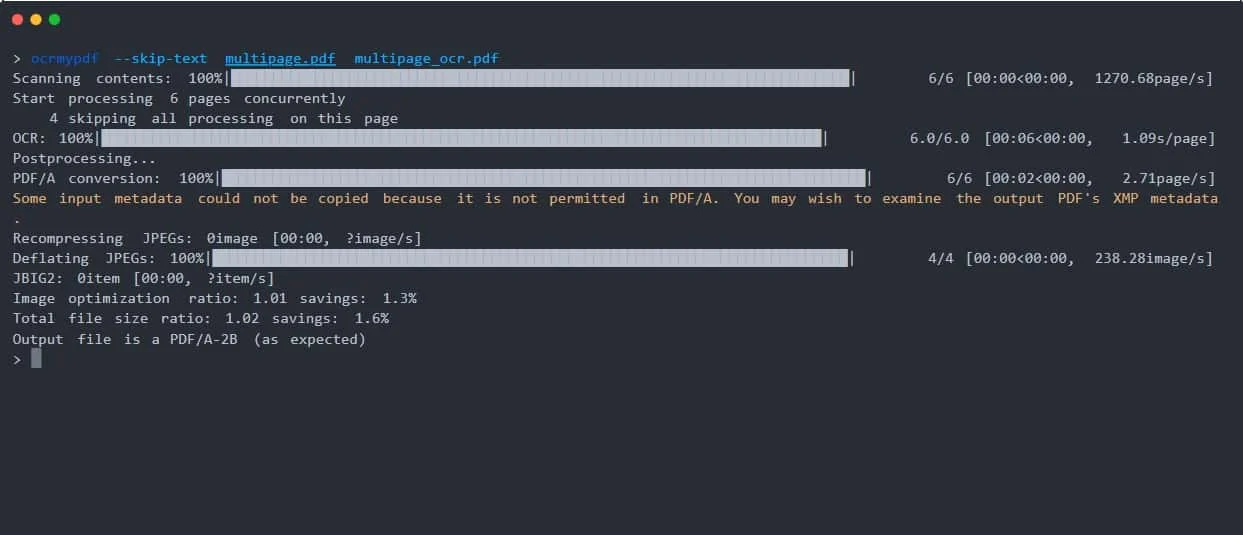
キー機能
- OCRテキストレイヤースキャンしたPDFを検索可能なPDF/Aフォーマットに変換し、テキスト検索やコピーが簡単に行えます。
- 多言語サポート100以上の言語に対応。
-lパラメータで言語を指定します(例-l eng+fra(英語とフランス語に対応)。 - 画像の最適化OCR中にPDF画像を最適化すると、通常、元のファイルよりも小さいPDFファイルが作成されます。
- ページ修正斜めページの自動回転をサポート (
--rotate-pages)、ページの折れ曲がりの修正(--デスキュー). - マルチコア処理マルチコアCPUによりOCR処理を高速化し、処理効率を向上。
- プライバシーユーザーの個人情報が漏洩しないようにする。
- バッチファイル数千ページを含む大きなPDFファイルを効率的に処理する能力。
こんな方におすすめ
- サラリーマンスキャンした紙文書を編集可能な電子文書に変換する必要がある。
- 図書館またはアーカイブ大量の歴史的文書をデジタル化する必要性。
- 開発者独自のアプリケーションにOCR機能を統合したい。
- 愛用者スキャンしたPDF文書を扱う必要のある個人ユーザー。
インストール
OCRmyPDFはLinux、Windows、macOS、FreeBSDを含む複数のオペレーティングシステムをサポートしています:
- Debian/Ubuntu::
apt インストール ocrmypdf - macOS (ホームブリュー)::
ocrmypdf をインストールする - Linux用Windowsサブシステム::
apt インストール ocrmypdf - ドッカーx64 および ARM アーキテクチャ用のミラーが利用可能です。
その他のインストール・オプションは官方文档.
概要
OCRmyPDFは、スキャンしたPDFファイルを検索可能な電子文書に変換する強力で使いやすいツールです。個人ユーザーでも企業でも、文書処理の効率を向上させるために使用することができます。スキャンしたPDFファイルを頻繁に扱う必要がある場合、OCRmyPDFは間違いなく試してみる価値があります。
公式サイトリンク
📢 免責事項|ツール使用上の注意事項
1️⃣ 本記事の内容は掲載時点で判明している情報に基づいており、AIの技術やツールは頻繁に更新されるため、最新の公式説明書をご参照ください。
2️ ⃣ 推奨ツールは基本的なスクリーニングは受けていますが、深いセキュリティ検証は受けていませんので、ご自身で適合性とリスクを評価してください。
3️⃣ サードパーティのAIツールを使用する際は、データプライバシー保護に注意し、機密情報のアップロードを避けてください。
4️ ⃣ 本サイトは、ツールの誤用、技術的な障害、コンテンツの逸脱による直接的/間接的な損害について責任を負いません。
5️🏣ツールによっては有料会員登録が必要な場合があります。合理的な判断をお願いします。当サイトは投資アドバイスを含むものではありません。